
Quite a bit to unpack here, but I’ll do my best. First things first though, it is becoming increasingly clear that network fabrics are key components to the performance of AI Compute Clusters. AI Fabrics demand special requirements such as low latency, lossless performance and lots and lots of bandwidth. The massive parallel data and application processing requirements of GenAI are driving, this exponential requirement overhead on front and back end fabrics. What was once really just the purview of niche and proprietary InfiniBand HPC environments, is quickly becoming center stage for all enterprises, together with a clear shift towards Ethernet.
Bottom Line GPU’s are getting larger and demand more bandwidth, so the networking stack must adapt to meet these new requirements. The amount of data flowing from GPU to GPU and server to storage is growing exponentially. The other point to note is that these are end to end requirements, from server, to NIC, to Switch , to the overarching Networking Operating System that knits all these components together. In order to deliver a performant end to end solution, we need an end to end approach. Enter the Dell AI Fabric…. and its foundation Dell AI fabric Infrastructure.
So what was announced?
I’ll dig into the deep weeds around topics such as Lossless fabric enablement, Intelligent load balancing/routing (plus cognitive routing. Mentioned by Michael Dell at the DTW keynote yesterday!) and end to end compute layer integration with RoCEv2, amongst others in future posts. For now though let’s overview some highlights, with a somewhat deeper nod to key new features….. As usual, I have attached some links to key content and other blogs….

So what do these new enhancements to the integrated fabric look like?
Dell Z9864F-ON with Enterprise SONiC 4.4

Key Hardware/Software Features
- 102.4Tbps switching capacity (full duplex), 51.2Tbps non-blocking (half-duplex)
- Based on the latest Broadcom Tomahawk 5 chipset.
- Enables the next generation of unified data center infrastructure with 64 ports of 800GbE switching and routing. It can also be used as a 100/200/400 switch via breakout, allowing for a maximum of 320 Ports. Twice the performance of the current generation PowerSwitch.
- Six on-chip ARM processors for high-bandwidth, fully-programmable streaming telemetry, and sophisticated embedded applications such as on-chip statistics summarization.
- Unmatched power efficiency, implemented as a monolithic 5nm die.
- RoCEv2 with VXLAN
- Adaptive Routing and Switching
- Cognitive Routing support in hardware (delivered by future software release)
I’ve missed loads more but… as promised this isn’t a datasheet. Of course here is the link to the new datasheet.

Why this matters.
A couple of reasons:
- Backend Fabrics consume massive bandwidth. Design Goal #1: The higher the radix of your switch fabric the better. You want to strive for flat and dense connectivity where at all possible. This is a key design goal. In other words, the ability to pack in as much connectivity, at line rate, without having to go off fabric or introduce multiple tiers of latency inducing switches. The Dell Z9864F-ON with Enterprise SONiC 4.4, can connect up to whopping 8K GPU nodes in a single two-tier 400GB fabric. Expanding from the standard 2K in a 2 tier topology from the previous Tomahawk 4 based platform.
- Adaptive Routing and Switching (ARS). This is blog worthy topic in its own right but for now the bottom line: Design goal number 2: high throughput with low latency. AI/ML traffic flows, especially in the backend are characterised by a proliferation of East-West, machine to machine, GPU to GPU flows. AI/ML flows are also characterised by buffer and path filling Elephant flows, which if not managed properly can introduce loss and latency. These last two terms signal the death knell to AI/ML fabric performance. We need a mechanism to dynamically load balance across all available paths, to minimise the ill effects of elephant flows. Adaptive Routing and Switching (ARS) dynamically adjusts routing paths and load balances based on network congestion, link failures, or changes in traffic patterns. This ensures that traffic is efficiently routed through the network. So for those wondering, you may see the term Dynamic Load Balancing (DLB) used here instead. Both DLB and ARS can be used interchangeably.
- Cognitive Routing brings this path sharing intelligence one step further. Broadcom introduced Cognitive Routing in their industry-leading Tomahawk 5 chipset, the chip architecture underpinning the Z9684-ON. It builds upon the adaptive routing functions present in previous generations of Tomahawk products, emphasizing the performance needs of Ethernet-based AI and ML clusters. Supported in hardware as of this platform release, the true capability of this feature will be unlocked via future SONiC releases, post 4.4. For a lot more depth on this topic and how it works under the hood, follow the link to the following great post by Broadcom.
Bottom line… a higher radix, higher bandwidth switch fabric, denser connectivity with multiple line rate high bandwidth switch ports , and intelligent flow and congestion aware load balancing across all available paths at both a hardware and software layer leads to maximised bandwidth utilisation, minimised loss and reduced average and tail latency. Simple….net result…. enhanced job completion times and more responsive inferencing.
RoCEv2 with VXLAN
End to End RoCEv2 over L2 and Layer 3 networks have been around for a while with Dell Enterprise SONiC. They were designed originally for to meet the increasing popularity of converging storage over existing ethernet fabrics, but are now really gaining traction in other settings such as AI/ML backend and frontend networking.
Very long story short, traditional ethernet sucks when transporting storage or any loss intolerant application. Storage is loss intolerant, hence the rise of ‘lossless’ fabrics such as Fiber Channel. Ethernet on the other hand is a ‘lossy’ fabric, which relies on the retransmission capabilities of TCP/IP. In order to square the circle, and make ethernet lossless then a couple of QoS feature enhancements were introduced at the switch level over the past decade, including but not limited to the following:
- Priority Flow Control (PFC) – provides congestion management by avoiding buffer overflow and achieves zero-packet loss by generating priority-based pause towards the downstream switch.
- Enhanced Transmission Control (ETS) – allocates specific bandwidth to each class of service to prevent a single class of traffic hogging the bandwidth.
- Explicit Congestion Notification (ECN) – marks packets when the buffer overflow is detected; end hosts check the marked packet and slow down transmission.
- Data center bridging protocol – operates with link layer discovery protocol to negotiate QoS capabilities between end points or switches.
In layman’s terms, ethernet now had a mechanism of priortising storage flows via DSCP and ETS, pause sending packets to the next switch when it detects congestion and telling its neighbors when its buffers are about to fill (PFC and ECN), and agreeing a common language between switches in order to make sure everybody understands what is happening (DCB). Hey presto, I can send storage traffic from switch to switch without loss….
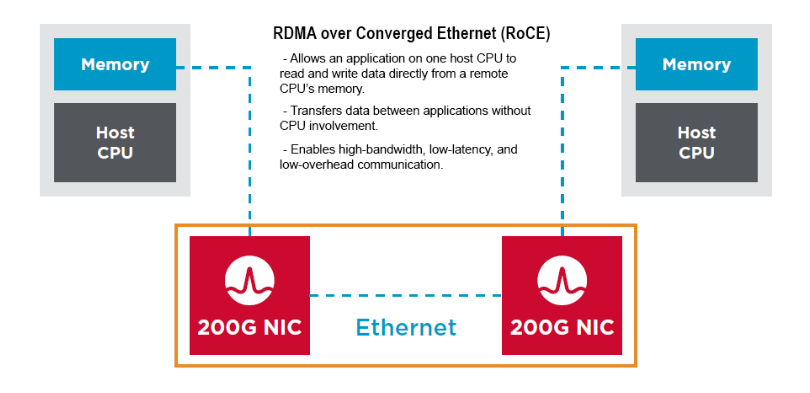
On the server side, in order to drive low latency outcomes, organisations are using RDMA ( Remote Direct Memory Access), in order to bypass the CPU delay penalty and achieve end to end, in memory inter communication between devices. When coupled with a converged ethernet fabric, as described above we get, drum roll……., RDMA over Converged Ethernet, and its latest iteration RoCEv2.
The key point here is that this is an end-to-end protocol, from the RoCE v2 capable sending NIC (did I mention the Thor 2 yet ), right across the DCB enabled Dell SONiC 4.4 Fabric ( Lossless Fabric), to the receiving end RoCEv2 enabled NIC. All components understand the common DCB language and the can respond dynamically to control notifications such as ECN ( Explicit Congestion Notification) and PFC (Priority Flow Control).
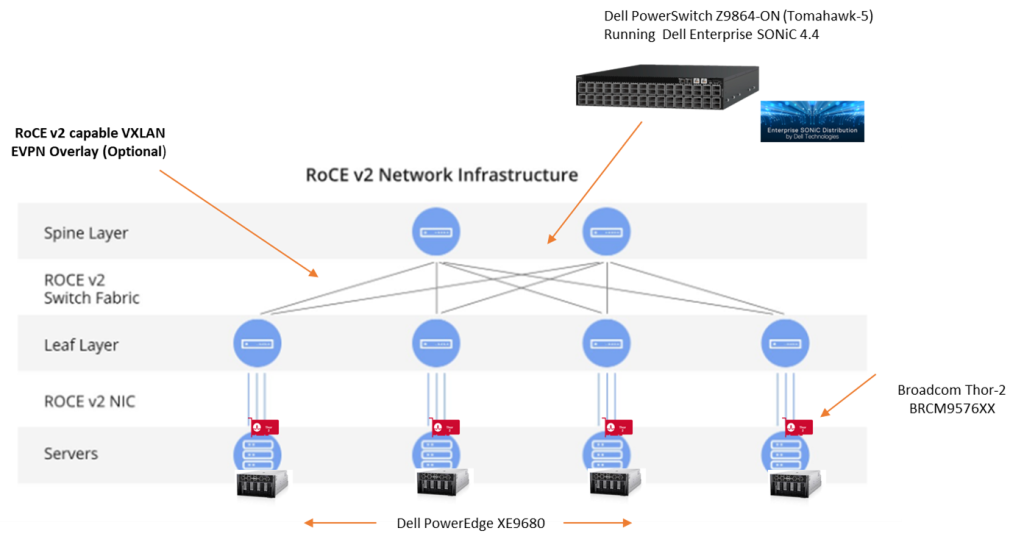
Where does VXLAN come into the picture?
Dell Enterprise SONiC has supported end to end RoCE v2 for some time now over traditional L2 and L3 transports. Release 4.4 however, adds the capability to add lossless fabric behavior, via end to end RoCE v2 over a VXLAN fabric. EVPN-VXLAN’s are extremely popular and well deployed in the enterprise, in order to achieve massive scale, segmentation, multi-tenancy and fault domain minimisation, amongst other advantages. In short it does this via encapsulating layer 2 traffic in a Layer 3 UDP packet ( VTEP & VXLAN Overlay), and controlling/distributing endpoint reachability information ( L2 MAC and L3 IP), via MP-BGP (Multiprotocol Border Gateway Protocol)…. phew, much to unpack there. Suffice to say, popular and powerful.
SONiC 4.4 now allows the ability to classify, switch and route RoCE v2 traffic received on an ingress VTEP, and impart that detail into the VXLAN overlay or tunnel. In short it is ECN/PFC aware and allows the VXLAN fabric to inherit the end to end lossless capabilities of traditional L2 switched or L3 routed networks.
Broadcom Thor-2: High Performance Ethernet NIC for AI/ML
As mentioned RoCE v2 is and end to end construct and hence the importance of the server side NIC. Coming Dell PowerEdge support of the Thor-2 network Adapter, rounds out the solution at scale. ( Apologies for the diagram.. this is actually 400GB!)
Features include:
- Support for RDMA over Converged Ethernet (RoCE) and congestion control, which are critical for AI/ML workloads.
- The ability to handle 400 gig bi-directional line rates with low latency to ensure rapid data transfer.
- PCIe Gen 5 by 16 host interface compatibility to maintain high throughput.
- Advanced congestion control mechanisms that react to network congestion and optimize traffic flow.
- Security features like hardware root of trust to ensure only authenticated firmware runs on the NIC.
I’ll blog in a future post more about the Thor-2 but for now, this is a great Cloud Field Day video link which sheds some more light on the incredible capabilities, and importance of the NIC in the end to end AI/ML architecture at scale.

Summing Up
Brevity is beautiful as they say, so for now I’ll pause and recap.
- Enterprise AI/ML workloads demand high radix, line rate, high bandwidth and intelligent switching fabrics to handle the exponential growth of inter GPU traffic and server to server AI/ML workloads at the backend, in order to satisfy training, re-training and inferencing. ( East -West Traffic )These workloads are incredibly sensitive to latency, most especially tail latency. The end to end Dell AI factory infrastructure network layer addresses these needs both in hardware and software through the introduction of the massively scalable Tomahawk-5 based Z9664F-ON switching platform, coupled with Adaptive Congestion Control enhancements and the future capability to deliver cognitive routing at line rate scale.
- The introduction of the Thor-2 based 400GB NIC rounds out the end to end line rate interconnectivity story between server GPU and switchport. No more oversubscription rather line rate end to end. Intelligent scheduling, telemetry and rate control features inbuilt into the NIC, together with ROCE v2 support and enhancements, deliver a true end to end non blocking, non oversubscribed lossless fabric.
- The addition of ROCE v2 support for VXLAN BGP-EVPN based fabrics. This allows enterprise customers to now couple lossless end to end ethernet with the multitenancy, scale and performance of overlay based switched fabrics.
I’ve missed loads, so much more to unpack. I’ll pick this up again in Part 2, with a deeper technical overview of the features of Dell Enterprise SONiC and Smart Fabric Manager in particular. AI networks demand deep insights, simplified management and cohesive automation at scale in order to deliver end to end intent based outcomes. Hopefully, you can see that, even for the most seasoned infrastructure pro, you need a factory type approach, in order to deliver the infrastructure required to underpin AI workloads.
Additional Links:
- Link to Petri Versunen’s blog at DTW 2024
- Dell Enterprise SONiC landing page
- Broadcom Cloud Field Day on the new Thor-2 NIC
- Dell blog on Ultra Ethernet Consortium
- Broadcom tech Blog on Cognitive Routing with the TH-5 chipset
- Z9664F-ON Data Sheet ( hey – who doesn’t love a good data sheet!)
- How Dell makes the AI Factory Real Blog
- Dell AI Factory Enhancements Blog
DISCLAIMER
The views expressed on this site are strictly my own and do not necessarily reflect the opinions or views of Dell Technologies. Please always check official documentation to verify technical information.
#IWORK4DELL
